
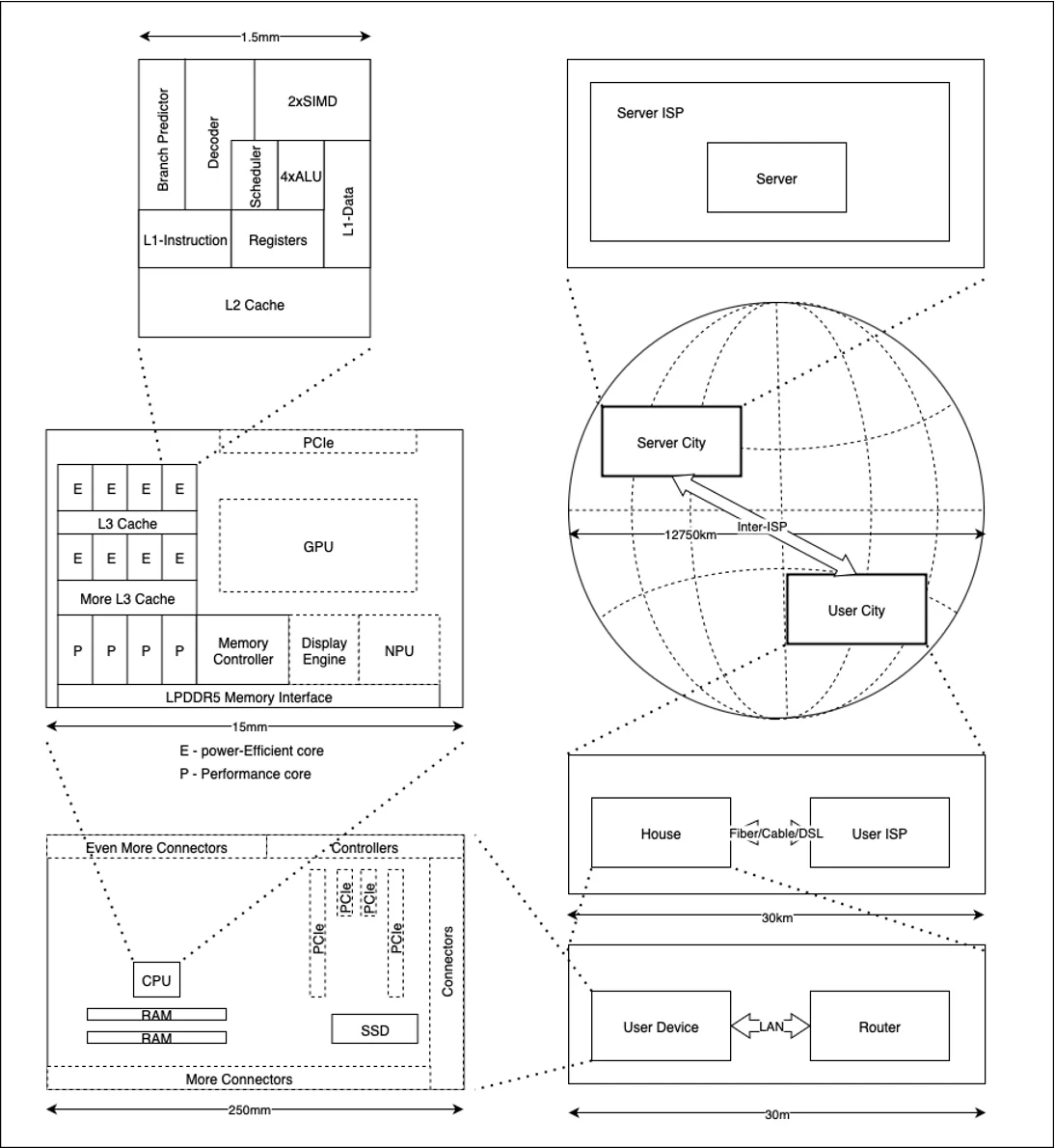
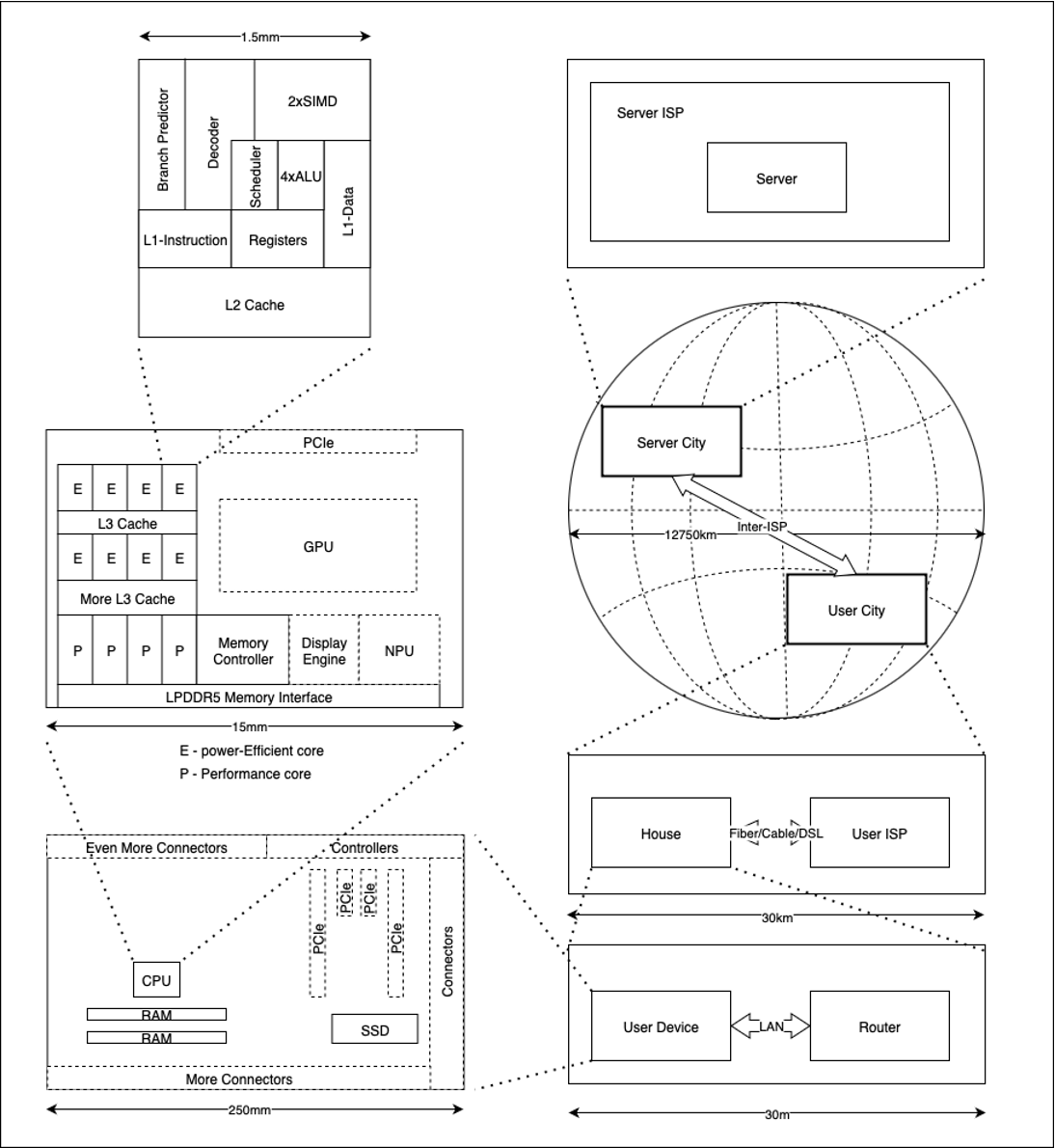
This article presents an excerpt from Chapter 4 of the forthcoming book, "Efficient C++ Programming for Modern 64-bit CPUs," authored by Sherry Ignatchenko and Dmytro Ivanchykhin. The authors invite technical feedback from the community regarding the factual accuracy of the principles discussed.
The Physics of Performance: Why Distance Defines Speed
"Another benefit of striving for efficiency is that the process forces you to understand the problem in more depth," once remarked Alex Stepanov, the architect of the original Standard Template Library (STL). As software engineers, we often abstract away the hardware, treating the CPU as a magical box that executes instructions instantaneously. However, modern 64-bit architecture is bound by the rigid, unforgiving laws of physics.
To understand the performance of a 2026-era CPU, we must first postulate a universal law: the farther an electrical signal must travel, the slower the access. While we often hear that electronics are limited by the speed of light, that is not the primary bottleneck at the scale of a silicon die. A signal traveling 0.5mm at the speed of light takes roughly 3 picoseconds. Yet, a typical register-to-register (R-R) operation consumes roughly 300 picoseconds—two orders of magnitude slower. The culprit is not the speed of light, but parasitic capacitance. The longer the connection, the higher the capacitance, and the more energy and time required to toggle the voltage state of the line.

Core Mechanics: Pipelining and Superscalar Execution
In the internal architecture of a "representative" CPU core, we encounter the Arithmetic Logic Unit (ALU). When we execute code like a += b;, the CPU is performing an R-R operation. Because modern 64-bit CPUs are deeply pipelined, the data required by the ALU is often waiting at the ALU’s entrance before the instruction even reaches the execution stage.
The Myth of Integer Cycles
Modern CPUs are "superscalar," meaning they feature multiple ALUs and SIMD units. This allows the processor to execute multiple instructions in parallel within a single clock cycle. This architectural complexity often leads to the counter-intuitive observation in micro-benchmarking where an operation appears to take a non-integer number of cycles (e.g., 0.75 cycles). This does not mean the operation finished in less than one clock tick; rather, it indicates that, statistically, the CPU successfully arranged the throughput so that four operations were completed every three cycles. While a theoretical "Retired Instructions Per Cycle" (RIPC) might reach 10–12, achieving a consistent 4 is a significant challenge, typically reserved for ALU-bound algorithms rather than memory-bound ones.
The Cache Hierarchy
Moving outside the registers, the CPU relies on the L1 Data (L1D) and Instruction (L1I) caches. Reading from L1D typically costs about 3 CPU cycles. Conversely, writing to L1D is effectively "instant" from the execution pipeline’s perspective, as the CPU merely issues a "store" command and moves on without waiting for confirmation. If the data is not in L1, the CPU must fetch it from L2 (10–15 cycles) or L3 (30–70 cycles).
Branch Mispredictions: The Software Developer’s Burden
While instruction execution is highly optimized, branch instructions (like JZ or BEQ) represent a major performance hurdle. Because the CPU cannot wait for the condition to be calculated, it uses "speculative execution." It guesses the path the code will take and proceeds. If the guess is correct, performance remains fluid. If the guess is wrong—a "branch misprediction"—the CPU must flush the entire pipeline, discarding all work performed on the incorrect path. This recovery process is costly, typically incurring a penalty of 15–25 cycles.
The Limits of [[likely]] and [[unlikely]]
Developers often reach for C++20’s [[likely]] and [[unlikely]] attributes to guide the compiler. However, their efficacy is frequently overstated. Modern CPUs employ "dynamic branch prediction," which tracks the history of branches at runtime. Since the hardware is already recording the actual frequency of outcomes, hard-coded hints are often redundant. We recommend using these attributes only when you are 200% certain of the outcome, such as in error-handling paths or specific mathematical edge cases (e.g., handling extreme input values in sin(x)).
Translation Lookaside Buffers (TLB) and Memory Access
Every memory access requires an address translation from virtual to physical space via the Memory Management Unit (MMU). This process is mediated by the Translation Lookaside Buffer (TLB). Because this occurs on every memory access, it is a critical performance path.

While TLB misses can be disastrous—potentially requiring a page-table walk all the way to main memory—they are rarely the primary bottleneck for application-level code. Developers can minimize DTLB pressure by favoring linear data structures (like std::vector) over node-based structures (like std::list or binary trees). In long-running, vector-oriented C++ programs, the performance degradation typically associated with cache-unfriendly pointer-chasing is significantly mitigated. For systems handling massive datasets, such as databases or JVM-based environments, "huge pages" remain the industry-standard solution for reducing TLB overhead.
The Hierarchy of Latency: From Cache to Cloud
To understand the full spectrum of performance, we must look at the hierarchy of latency from the core outward:
| Level | Latency (Approx. Cycles) |
|---|---|
| L1 Cache | ~3 |
| L2 Cache | ~10–15 |
| L3 Cache | ~30–70 |
| Main RAM | ~200–300 |
| NVMe SSD | ~30,000–45,000 |
| SATA SSD | ~240,000–300,000 |
| HDD (Seek) | ~30M–45M |
The "Outside World" Bottleneck
Once an operation leaves the motherboard and enters the network, we shift from CPU-cycle counting to physical geography. Accessing a local 1Gbit LAN takes ~100k–500k cycles. Crossing the continent, such as from Toronto to Perth, introduces latencies in the range of 750 million cycles—a quarter of a second. In these scenarios, the speed of light becomes the primary constraint, and "user patience" becomes the ultimate performance metric.

Implications for Modern C++ Development
The primary takeaway for the C++ developer is the necessity of "de-pessimizing" code. We must prioritize cache-friendly memory layouts and minimize branch unpredictability. As we have seen, the cost of going "off-chip" or "off-node" is exponential.
While architectural innovations like System-on-a-Chip (SoC) designs—such as the Apple M-series—have attempted to unify memory access and reduce latencies, they remain bound by standardized interfaces like LPDDR5X. Ultimately, the gap between a 3-cycle L1 access and a 300-cycle RAM access is the fundamental challenge of modern software performance.
A Note on Reliability and FMEA
For database engineers, understanding the durability costs of fsync() is paramount. An enterprise-grade RAID controller with battery-backed cache can perform a full ACID write in ~120,000 cycles, whereas a standard SATA SSD might take over a million. Understanding these failure modes—and the cost of ensuring consistency—is essential for any developer operating at the intersection of high-performance computing and persistent storage.

In conclusion, performance is not merely about writing faster algorithms; it is about respecting the physical architecture of the machine. By aligning our data structures with the hardware’s cache hierarchies and minimizing the distance signals must travel, we can unlock the true potential of modern 64-bit CPUs.
