
In the high-stakes world of cloud-native computing, the difference between a seamless user experience and a system outage often comes down to seconds. Amazon Web Services (AWS) has long been the gold standard for container orchestration via Amazon Elastic Container Service (ECS). Today, AWS is fundamentally shifting the performance benchmark for container management by introducing high-resolution (20-second) metrics for ECS Service Auto Scaling. This update represents a significant leap forward in how applications respond to sudden traffic spikes, offering a level of responsiveness that was previously unattainable for many high-demand workloads.
The Evolution of Elasticity: Main Facts
For years, Amazon ECS has provided robust auto-scaling capabilities, allowing users to align their resource consumption with real-time demand. Traditionally, these systems operated on 60-second intervals. While sufficient for many steady-state applications, the minute-long delay in data collection and subsequent scaling action often left "bursty" applications vulnerable to latency spikes or service degradation during the time it took to provision new tasks.
The new update drastically changes this paradigm. By moving to 20-second metrics, AWS is essentially tripling the frequency at which the system evaluates health and performance data. This enhancement is not merely a cosmetic change; it is a fundamental shift in the control loop of Amazon ECS. The update applies to all compute options within the ECS ecosystem, including AWS Fargate, ECS Managed Instances, and standard Amazon Elastic Compute Cloud (EC2) instances.
This feature is designed to empower developers who manage applications where traffic can fluctuate violently within a single minute. By enabling high-resolution metrics, users can now ensure that their infrastructure is not just reacting, but reacting at the speed of modern business requirements.
A Timeline of Performance: The Chronology of Optimization
The journey toward this release reflects the broader trajectory of AWS’s commitment to "Operational Excellence." Over the past several years, the engineering teams at AWS have focused on reducing the "time-to-provision" for containerized workloads.
- The Foundation (Pre-2024): Amazon ECS established itself as a leader in container orchestration with sophisticated strategies including predictive scaling (leveraging machine learning for anticipated load), scheduled scaling (for known events), and target tracking (reactive scaling based on CPU or memory thresholds).
- The Bottleneck Identification: As customer workloads grew more complex, particularly with the rise of microservices and event-driven architectures, AWS engineers identified that the 60-second metric resolution was a limiting factor in the "trigger-to-provision" timeline.
- The Testing Phase: Throughout 2024 and early 2025, AWS conducted extensive internal benchmarking to measure the impact of shifting the metric polling interval. These tests focused on the entire lifecycle of a scaling event—from the moment a load threshold is crossed to the moment a container is ready to serve traffic.
- The Breakthrough (Current Release): Today marks the official rollout of 20-second metric resolution for ECS Service Auto Scaling. This integration allows users to opt into higher-resolution data streams through the AWS Management Console, SDKs, or Infrastructure as Code (IaC) tools like AWS CloudFormation.
Beneath the Surface: Supporting Data and Benchmarking
The most compelling argument for adopting this new feature lies in the raw performance metrics released by AWS. In a direct comparison between the legacy 60-second resolution and the new 20-second high-resolution monitoring, the improvements are substantial.
According to official AWS benchmarking tests:
- Trigger Time Improvement: The time required to trigger a scale-out event plummeted from 363 seconds to 86 seconds. This represents a 76% reduction in latency, effectively accelerating the response time by a factor of 4.2x.
- End-to-End Provisioning Speed: The total time required to scale, provision, and reach a "ready" state for new tasks improved from 386 seconds to 109 seconds. This 72% improvement (3.5x faster) ensures that applications remain stable even when traffic surges unexpectedly.
These figures illustrate a critical point: the bottleneck in scaling was rarely the underlying infrastructure—it was the decision-making loop. By tightening the feedback cycle, AWS has unlocked a significant portion of unused performance, allowing ECS users to maintain higher service levels with less over-provisioning.

Expert Perspectives: Official Responses and Strategic Vision
Channy Yun, a Principal Developer Advocate at AWS and a key voice in the evolution of these services, highlighted the simplicity of the transition. "This launch delivers three key benefits for your applications," noted Yun, emphasizing that the focus remains on reducing the operational burden on developers while maximizing performance.
The strategy behind this update is clear: AWS aims to make high-performance auto-scaling a "low-code" or "configuration-based" task rather than an architectural challenge. By exposing these options directly within the ECS service creation flow, AWS is encouraging a broader adoption of reactive, high-resolution scaling across its user base.
The official documentation suggests that while the feature is simple to toggle, it is a powerful tool for cost optimization. By scaling more accurately and quickly, users can maintain leaner fleets of containers, potentially reducing the overall footprint required to handle peak loads.
Implications for Modern Architecture
The introduction of 20-second auto-scaling has profound implications for the future of cloud-native architecture.
1. Enhanced Reliability for Microservices
In a distributed microservices environment, a single service failure can cascade if the surrounding services do not scale fast enough to compensate for the shifted load. Faster auto-scaling serves as a shock absorber, ensuring that the system can rebalance itself before a minor spike becomes a major system-wide failure.
2. Cost-Effective Over-Provisioning
Historically, developers have often chosen to "over-provision" their ECS clusters—running more tasks than necessary—as a buffer against slow scaling. This "buffer" is expensive. With faster auto-scaling, the need for this safety margin decreases, allowing companies to run leaner, more cost-efficient clusters without compromising on performance.
3. Enabling "Burstier" Workloads
Applications that were previously considered "unfit" for auto-scaling due to their unpredictable or instantaneous traffic patterns can now be safely hosted on ECS. This opens the door for real-time data processing, gaming backends, and high-frequency trading platforms to leverage the agility of managed containers.
4. Financial Considerations
While the feature itself carries no additional AWS service cost, it is vital for organizations to understand the pricing dimension of high-resolution CloudWatch metrics. High-resolution metrics collect data more frequently, which results in a higher volume of data points sent to the CloudWatch service. For massive deployments, this will reflect on the monthly AWS invoice. However, for most organizations, the cost of these metrics will be dwarfed by the savings achieved through more efficient task management and improved application uptime.
Implementation: A Quick Start Guide
For teams looking to integrate this immediately, the process is streamlined for both new and existing services:
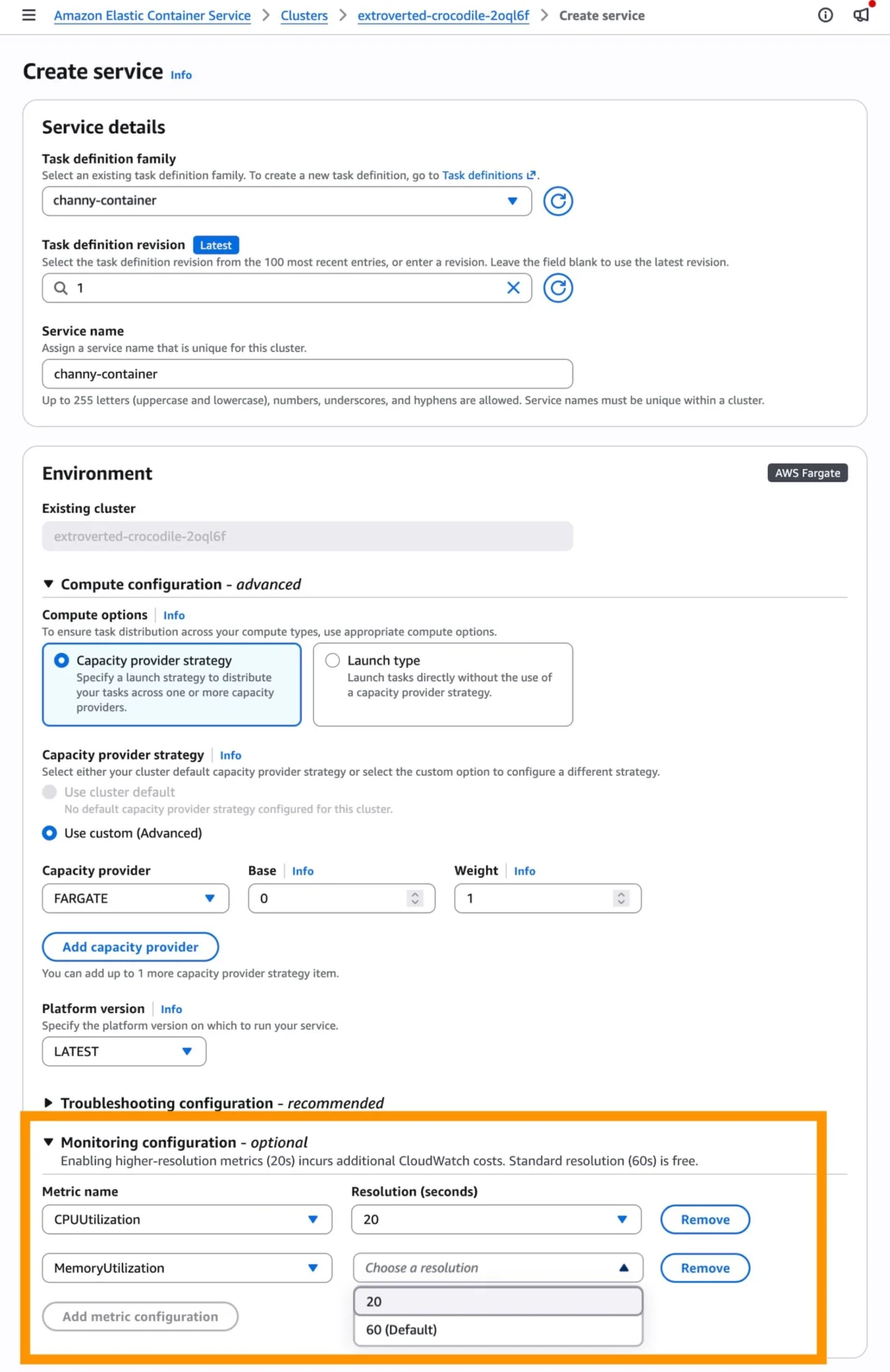
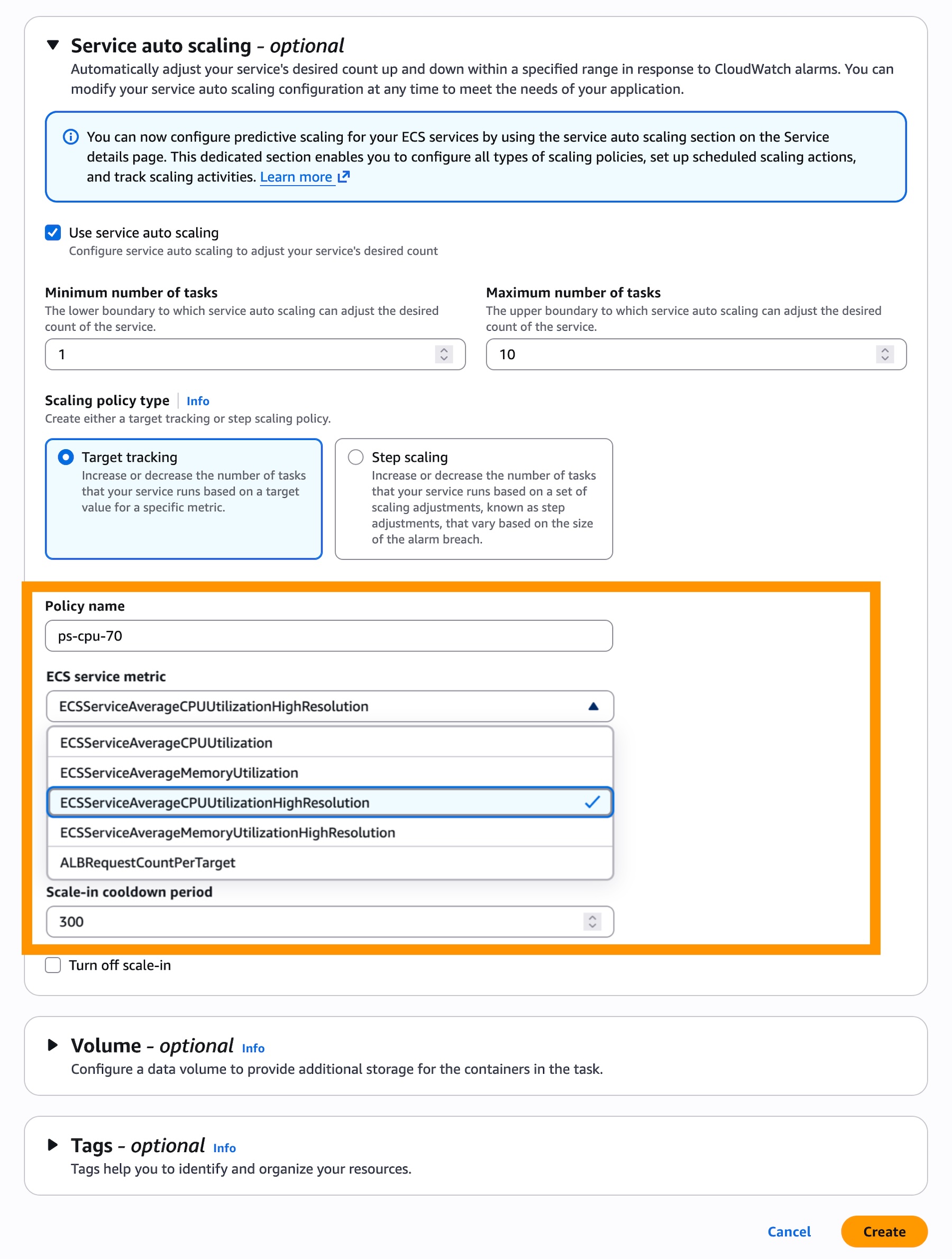
- For New Services: Simply navigate to the "Monitoring configuration" section during the service creation process in the AWS Console. Select the option for 20-second resolution metrics. Once configured, select
ECSServiceAverageCPUUtilizationHighResolutionorECSServiceAverageMemoryUtilizationHighResolutionas your target tracking metric. - For Existing Services: Update the service via the "Update Service" workflow to enable high-resolution metrics. Once the deployment propagates, navigate to the "Service and auto scaling" tab to point your existing target tracking policies toward the new high-resolution metrics.
Conclusion
The release of 20-second high-resolution metrics for Amazon ECS is a hallmark of AWS’s "customer-obsessed" approach to infrastructure. By identifying a specific pain point in the scaling lifecycle and engineering a solution that provides a 3.5x improvement in response time, AWS has provided a vital tool for the next generation of high-demand, high-scale applications.
As the digital landscape becomes increasingly unpredictable, the ability to adapt in real-time is no longer a luxury; it is a necessity. With this update, AWS has once again set the bar for container orchestration, ensuring that developers can focus on building innovative features while the infrastructure handles the complexities of scale with unprecedented speed and precision.
