
In a landmark update for cloud-native data management, Amazon Web Services (AWS) has unveiled a transformative capability for its flagship object storage service, Amazon Simple Storage Service (S3). The introduction of "S3 Annotations" marks a paradigm shift in how enterprises attach, manage, and query rich business context alongside their data. By allowing users to append up to 1 GB of descriptive metadata per object—spanning formats such as JSON, XML, YAML, and plain text—AWS is effectively solving one of the most persistent bottlenecks in modern data architecture: the disconnect between massive raw datasets and the context required to make them actionable for artificial intelligence.
Main Facts: Redefining Object Storage Metadata
For years, Amazon S3 users have relied on a combination of system-defined metadata, user-defined headers, and object tags to organize their data. While efficient for basic lifecycle management or access control, these methods were never designed for the era of generative AI and autonomous agents. The traditional 2 KB limit on user-defined metadata often forced architects to build complex, expensive "sidecar" databases or external indexing systems just to keep track of what their data actually represents.
S3 Annotations fundamentally change this landscape. Key features of this new capability include:
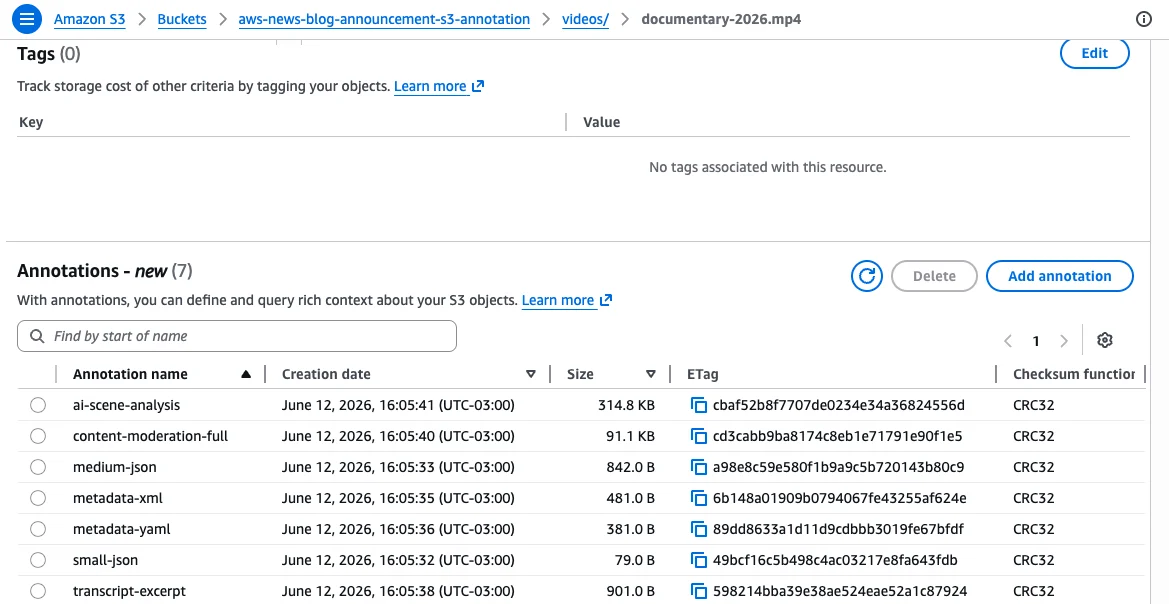
- Granular Capacity: Users can store up to 1,000 named annotations per object, with each annotation reaching up to 1 MB. This provides a total capacity of 1 GB per object, a massive leap over previous limitations.
- Mutable Context: Unlike traditional object tags or headers that are often set at upload, annotations can be updated, modified, or deleted at any time without requiring the user to re-write or re-upload the primary object.
- Seamless Portability: Annotations are intrinsically linked to the object. When a file is copied, replicated, or moved across regions, its annotations follow it automatically. If the parent object is deleted, the annotations are purged as well, ensuring consistent data lifecycle hygiene.
- Queryable Intelligence: Through S3 Metadata, these annotations are automatically indexed into managed Apache Iceberg tables. This allows organizations to leverage Amazon Athena and other analytics engines to query metadata at scale without the need for complex, manual synchronization.
Chronology: The Evolution of S3 Metadata
The journey toward S3 Annotations reflects the broader trajectory of cloud storage requirements. In the early days of AWS, S3 functioned primarily as a high-durability repository for static assets. As storage needs grew from gigabytes to petabytes, the necessity for structured metadata became apparent.
- The Early Era: Initially, S3 provided only basic system metadata (like file size and storage class). Users could add a small amount of custom information via headers, but these were largely static and limited to 2 KB.
- The Rise of Operational Tagging: As S3 became the backbone of enterprise storage, the need for cost allocation and lifecycle policies grew. Amazon introduced object tags, allowing users to categorize data for access control and cost management, though these were restricted to small key-value pairs.
- The AI Mandate: With the explosion of Large Language Models (LLMs) and autonomous AI agents, the industry hit a wall. AI models required massive amounts of context—transcripts, sentiment analysis, technical specs, and content ratings—to function effectively. Maintaining this data in separate, external SQL or NoSQL databases created a "synchronization tax" that drained engineering resources.
- The Present Day: The announcement of S3 Annotations bridges this gap. By moving the context directly into the storage layer, AWS has enabled a "metadata-first" approach to object storage, aligning perfectly with the needs of modern agentic workflows.
Supporting Data: Why Scale Matters
To understand the significance of S3 Annotations, one must look at the constraints they resolve. Traditional metadata solutions struggle under the weight of enterprise-scale data. The following table illustrates the dramatic shift in capability:

| Capability | Max Size | Mutable? | Best For |
|---|---|---|---|
| System Metadata | Fixed | No | Size, class, timestamps |
| User Metadata | 2 KB | No | Small key-value pairs |
| Object Tags | 10 tags | Yes | Lifecycle/Access control |
| Annotations | 1 GB | Yes | Rich business/AI context |
By providing a 1 GB threshold, S3 Annotations allow for the storage of complex, high-fidelity information. A media company, for instance, can now store a full technical schema, AI-generated transcriptions, and multi-language content summaries directly within the metadata, without ever touching the primary binary file. This eliminates the need for expensive "restore" operations from cold storage tiers, as the metadata remains queryable even if the underlying object is archived in S3 Glacier.
Official Responses and Strategic Implications
The introduction of S3 Annotations has been met with enthusiasm from data architects and AI developers alike. According to Daniel Abib, the lead architect behind the feature, the primary goal was to empower "agentic workflows."
"Organizations are building AI agents and autonomous workflows that need to find, understand, and act on data without human intervention," Abib noted during the announcement. "To support these, you need metadata that can evolve alongside the data, scale to petabytes of objects, and remain queryable without expensive retrieval."
The strategic implications are profound. By leveraging the S3 Tables MCP server, AI agents can now perform "discovery" tasks using natural language. Instead of a developer writing a complex query to search through an external database, they can task an AI agent to "Find all PG-rated movies with Spanish subtitles from 2023." The agent communicates with the S3 metadata table, retrieves the relevant objects, and presents the results in seconds.
Implications for Industry and Compliance
The ripple effects of this update are likely to be felt across several sectors:

Media and Entertainment
With petabytes of raw video, media companies previously faced the daunting task of maintaining a separate media asset management (MAM) database. With annotations, technical specs (codecs, frame rates, audio tracks) can be updated in real-time as video content is processed, ensuring that downstream AI editing tools always have the most current information.
Legal and Compliance
For organizations handling massive volumes of archived documentation, tracking compliance context—such as "Legal Hold" status, privacy classification, or retention expiration—often involved brittle, external auditing logs. With S3 Annotations, this sensitive context is now natively attached to the object and can be queried for audits without scanning the files themselves.
AI Development and Machine Learning
The most significant impact is on the "data prep" phase of machine learning. By storing feature metadata (like model training labels or confidence scores) directly as annotations, data scientists can maintain an audit trail of how a specific dataset was curated, facilitating more transparent and reproducible model training.
Implementing Annotations: A Practical Path Forward
Transitioning to this new architecture is designed to be seamless for existing AWS users. The implementation involves a few key steps:
- Permission Configuration: Administrators must update IAM or bucket policies to include
s3:PutObjectAnnotationands3:GetObjectAnnotationpermissions. - API Integration: Users can add metadata using the AWS CLI or SDKs. For example, attaching a JSON-based technical spec to a video file is as simple as:
aws s3api put-object-annotation --bucket my-media-bucket --key videos/documentary.mp4 --annotation-name mediainfo --annotation-payload ./mediainfo.json - Enabling Metadata Tables: By enabling S3 Metadata annotation tables, the data is automatically synced into Apache Iceberg format. This allows for powerful SQL queries via Amazon Athena:
SELECT DISTINCT bucket, object_key FROM "s3tablescatalog/aws-s3"."b_my_media_bucket"."annotation" WHERE name = 'mediainfo' AND CAST(json_extract_scalar(text_value, '$.audio_tracks') AS INTEGER) > 8
Looking Ahead: The Future of Metadata-Driven Storage
As enterprises continue to shift toward autonomous AI architectures, the "data lake" is evolving into a "data brain." Amazon S3 Annotations provide the cognitive layer necessary for this evolution. By removing the wall between storage and context, AWS has set a new standard for how data is described and discovered.
While the feature is currently rolling out across all AWS regions, its long-term impact will be measured in the efficiency of the AI workflows it enables. By reducing the reliance on external, disconnected databases, S3 Annotations simplify the cloud infrastructure stack, lower operational costs, and, most importantly, provide the high-fidelity context that is the lifeblood of the modern artificial intelligence economy.
For organizations struggling with the "data sprawl" of the last decade, this is more than just an API update—it is the essential infrastructure required to turn raw, silent bytes into an organized, searchable, and intelligent corporate asset. As the industry continues to integrate S3 Annotations into their pipelines, the gap between data creation and data intelligence is set to close significantly.
